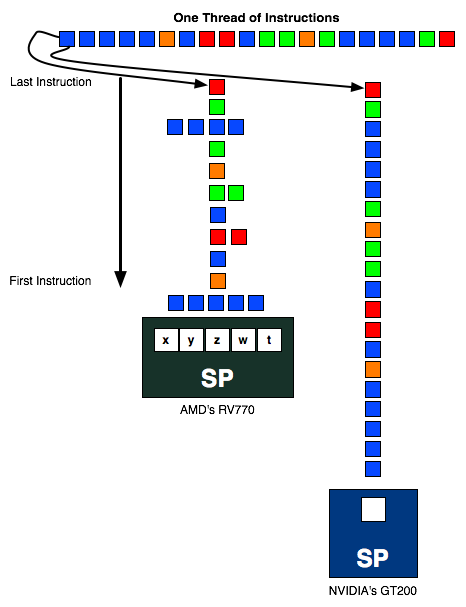
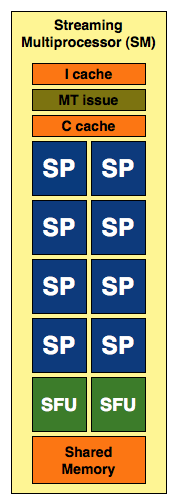
Ima tu neke istine. ne rade uvek svih 800, a zasto to najbolje zna ATI. Bice da treba doterivati drajvere, ali o iskoriscenju svih 800 uvek i svuda nema govora. Ako koristi i 50% u proseku odlicno je. Naravno prosek je statistika, a statiskika je k*rva, tako da moze da "izuva", a moze i da prodje k'o bosa po trnju. evidentno je da u shader intenzivnim igrama (Assassin's Creed, COD4, Oblivion...) radi odlicno, dok u onim jednostavnijim, a samim tim manje pogodnim za "paralelizam", dolazi do losijeg koriscenja svih 800 i nesto manje konacne brzine. Sad cu bas banalizovati problem i ako nema veze sa ovim sto cu napisati, ali je slikovito. Zamislite malog Djokicu kako uzima kemencice, po 5 komada i baca ih sa 3 metara u bure, a sa druge strane zamislite Pericu, Jovicu i npr. Ivicu kako uzimaju po jedan kamencic i bacaju ga u to isto bure. Djokica baca i 2-3 upadaju (ponekad samo jedan, a ponekad i svih 5), jer se rasipaju, a mali Perica, Jovica i Ivica sigurno ubacuju sve unutra bacajuci po 1 kamencic. U finalnom skoru posto je bure daleko (citaj nepogodan kod) Djokica izvlaci deblji kraj i gubi od klinaca, ne mnogo, ali gubi. A sada se situacija menja i bure se namesta na 1m. Sada i Djokica ubacuje uvek svih 5 kamencica (tek ponekad promasi). Sada mali DJokica odnosi pobedu. Shvatite ovo kao "pogodniji" kod. Ispada da sve shader intenzivne igre vole 4000 seriju (Assassin's Creed, COD4, Oblivion..), a verujem da ce ih u buducnosti biti sve vise. Jedini primer koji se ne uklapa je Crysis, ali on se brate ne uklapa nigde, to je teski nogokuc od igre. Probao sam za vikend 2x 9600GSO i daju celih 22fps u High 1280x1024 sa 4xAA, dok 4850 daje celih 33fps. Tragicno je u celoj prici sto jedna 9600GSO daje 19fps. ispada da je od SLI ubrzanje svega 15%?!?! Prva igra za koju zaista trebaju ili SLi ili CF i corak. Moram napomenuti da sam za 4850 u 3Dmarku03 napravio 40000 (znam, los mi CPU), a da su 2x9600GSO napravile 48800!!! Isto tako i SM3 skor 3Dmarka06 daje umesto 4200 6200 (opet mi slab CPU), dok 4850 ima 5300 (znam, znam, nejaki Athlon). Ajd da ne davim vise. Odo!! :wave: